SGD Optimizer - Implementation and Testing:-
09 Jul 2018In this blog post, I will be explaning the implementation of the SGD Optimizer with and without momentum approach. I will also be explaning the methodology I used for testing the correctness of the optimizer.
SGD Optimizer:
Stochastic Gradient Descent is the one of the basic optimization algorithms that is used for training the Deep Neural Networks. I have implemented the SGD Optimization algorithm with and without momentum method. The finalized class diagram for the VOptimizer class and the TSGD class, which is derived from the VOptimizer class is shown below,

Here, Step() function is implemented in the base class VOptimizer. And the UpdateWeights() and UpdateBiases() functions are pure virtual functions. So other optimizer classes extending from the base class VOptimizer, for example: TSGD class must implement the UpdateWeights() and UpdateBiases() functions. The fPastWeightGradients and fPastBiasGradients store the accumulation of the past weight and past bias gradients respectively.
Momentum Update:
With Stochastic Gradient Descent we don’t compute the exact derivative of our loss function. Instead, we’re estimating it on a small batch. This means we’re not always going in the optimal direction, because our derivatives are ‘noisy’. So, exponentially weighed averages can provide us a better estimate which is closer to the actual derivative than our noisy calculations. This is one reason why momentum might work better than classic SGD.
The other reason lies in ravines. Ravine is an area, where the surface curves much more steeply in one dimension than in another. Ravines are common near local minimas in deep learning and SGD has troubles getting out of them. SGD will tend to oscillate across the narrow ravine since the negative gradient will point down one of the steep sides rather than along the ravine towards the optimum. Momentum helps accelerate gradients in the right direction.
Thus, the momentum update is implemented as follows, ( similar to the tensorflow implementation )
accumulation = momentum * accumulation + gradient
variable -= learning_rate * accumulation
So, one step of update is performed as,
Testing the Optimizer:
And now, for testing the optimizer, there is no exact methodology that can be used. One possible approach would be to test the convergence of the training and testing error during the training procedure. So the unit tests is created as follows,
Let, X = Random Matrix ( nSamples x nFeatures ),
K = Random Matrix ( nFeatures x nOutput ),
Y = X * K ( nSamples x nOutput ) ( Generated one ).
I created a simple 3 layer DeepNet with the following architecture,

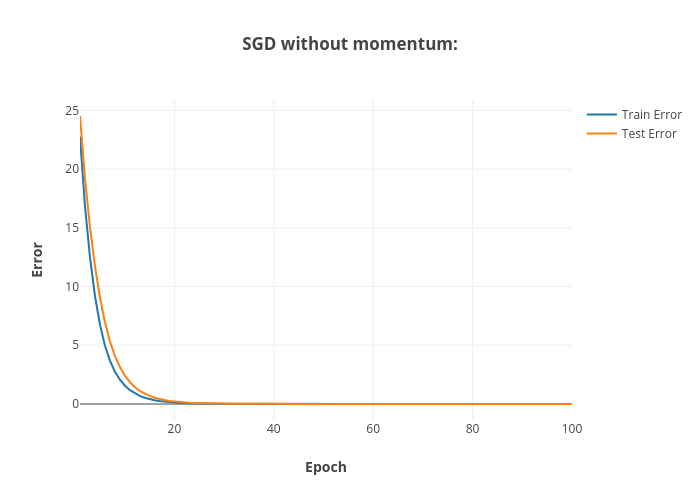
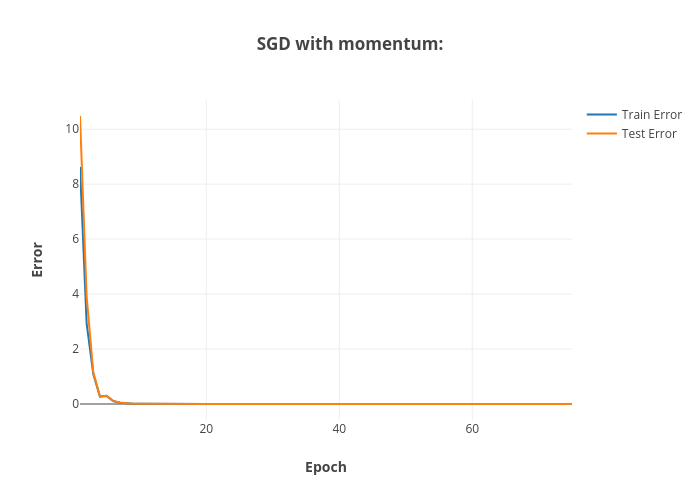
The above figures shows the convergence of the training and testing errors for the SGD optimizer without and with momentum during the unit tests.
Another method is to create a identity matrix I = Identity Matrix ( batchSize x nFeatures ) and give this as Input to the DeepNet and forward it and get the output at the last layer. Let this output be Y’ ( batchSize x nOutput ).
Now, Since the DeepNet is trying to mimic the function Y = X * K, this output Y’ should be equal to K. For this to be true, there is one constrain to be satisfied that the batchSize and nFeatures should be equal so that we can construct the Identity Matrix I as a square matrix with diagonal elements being equal to 1.0. And I got the following results by comparing the Y’ with K.
